- امور مالی یاهو
- آیا دلال کارگزار شما سیستم نظارتی کافی دارد؟
- معرفی تغییرات جدید به سبک مسطح برای گسترش. net Windows Forms 12
- فیس بوک فقط بدترین روز خود را در وال استریت داشت
- پیش بینی قیمت عسل ، پیش بینی HNY
- مدیریت ریسک در نمونه کارها شما
- اندازه گیری توافق داده های اداری با داده های نمودار با استفاده از شیوع غیر قابل تنظیم و تنظیم شده کاپا
- BBA (بازارهای مالی) در ارتباط با آکادمی NSE
- فرمول درآمد واقعی ، اثر و نمونه ها
- شاخص داو جونز چگونه محاسبه می شود؟

آخرین مطالب
امکانات وب


ذخیره سازی یک روش متداول برای سریعتر کردن برنامه های کاربردی شما است. این امکان را به شما می دهد تا با استفاده مجدد از نتایج قبلی ، از عملکرد آهسته خودداری کنید. در این مقاله ، آیو اشعیا ما را از طریق گزینه های مختلف برای ذخیره سازی در برنامه های NodeJS طی می کند.
ذخیره سازی فرآیند ذخیره داده ها در یک لایه ذخیره سازی پر سرعت است به گونه ای که درخواست های آینده برای چنین داده هایی با دسترسی به مکان اصلی ذخیره سازی آن بسیار سریعتر از حد ممکن انجام می شود. نمونه ای از ذخیره سازی که ممکن است با آن آشنا باشید ، حافظه نهان مرورگر است که به طور مکرر به منابع وب سایت به صورت محلی دسترسی پیدا می کند ، به طوری که نیازی به بازیابی آنها از طریق شبکه در هر بار که مورد نیاز نیست ، نیست. با حفظ حافظه نهان اشیاء در سخت افزار کاربر ، بازیابی داده های ذخیره شده تقریباً فوری است و منجر به افزایش سرعت و رضایت کاربر می شود.
در زمینه برنامه های سمت سرور ، ذخیره سازی هدف از آن با استفاده مجدد از داده های بازیابی شده یا محاسبه شده قبلی ، زمان پاسخ برنامه را بهبود می بخشد. به عنوان مثال ، به جای تکرار درخواست های شبکه برای داده هایی که اغلب یا به هیچ وجه تغییر نمی کنند (مانند لیستی از بانک های کشور خود) ، می توانید پس از درخواست اولیه ، داده ها را در حافظه پنهان ذخیره کرده و در درخواست های بعدی آن را از آنجا بازیابی کنیدبشراین باعث می شود درخواست های بعدی برای این داده ها به یک ترتیب از بزرگی منجر به بهبود عملکرد برنامه ، کاهش هزینه ها و معاملات سریعتر شود.
این مقاله با هدف ارائه مروری بر ذخیره سازی ، استراتژی های ذخیره سازی و راه حل های موجود در بازار ارائه شده است. پس از خواندن این پست ، شما باید تصور کنید که چه موقع حافظه پنهان ، چه چیزی را ذخیره کنید و تکنیک های مناسب برای استفاده در برنامه های Node. js خود بسته به استفاده از حروف استفاده کنید.
مزایای ذخیره سازی
فواید اصلی ذخیره سازی این است که با کاهش نیاز به بازآفرینی نتیجه یا دسترسی به لایه پردازش یا ذخیره سازی زیرین ، سرعت بازیابی داده ها را بهبود می بخشد. دسترسی سریعتر داده ها بدون افزودن منابع سخت افزاری جدید ، پاسخگویی و عملکرد برنامه را افزایش می دهد. مزایای دیگر موارد زیر را شامل می شود:
کاهش بار سرور: درخواست های خاص می توانند به زمان پردازش قابل توجهی در سرور نیاز داشته باشند. اگر نتیجه پرس و جو در حال حاضر در حافظه نهان وجود داشته باشد ، این پردازش را می توان کاملاً پرش کرد تا زمان پاسخ سریعتر باشد ، که منابع سرور را برای انجام کارهای دیگر آزاد می کند.
افزایش قابلیت اطمینان: تأخیر بالاتر هنگام بازیابی داده ها ، تأثیر معمول سنبله ها در استفاده از برنامه است که باعث عملکرد کندتر در سراسر صفحه می شود. تغییر مسیر بخش قابل توجهی از بار به لایه حافظه نهان به عملکرد کمک می کند تا بسیار قابل پیش بینی تر شود.
کاهش هزینه های شبکه: قرار دادن اشیاء مکرر در حافظه نهان ، میزان فعالیت شبکه ای را که باید فراتر از حافظه نهان انجام شود ، کاهش می دهد. این امر باعث می شود که داده های بسیار کمتری به منشأ محتوا منتقل شوند و منجر به پایین آمدن هزینه های انتقال ، تراکم کمتر در صف در سوئیچ های شبکه ، بسته های کم شده کمتر و غیره شود.
بهبود عملکرد پایگاه داده: یک یافته مشترک هنگام بررسی عملکرد برنامه این است که بخش قابل توجهی از زمان پاسخ کلی در لایه پایگاه داده صرف می شود. حتی اگر نمایش داده ها کارآمد باشند ، هزینه پردازش هر پرس و جو (به ویژه برای اشیاء که به طور مکرر دسترسی دارند) می توانند به سرعت به تأخیر های بالاتر اضافه کنند. یک راه عالی برای کاهش این مسئله ، دور زدن پردازش پرس و جو و استفاده از یک نتیجه از پیش تعیین شده از حافظه پنهان است.
افزایش در دسترس بودن محتوا: از حافظه پنهان می تواند به عنوان راهی برای حفظ در دسترس بودن داده های خاص استفاده شود ، حتی اگر ذخیره سازی داده های مبدا به طور موقت کاهش یابد.
چه موقع باید حافظه پنهان شود؟
ذخیره سازی ابزاری عالی برای بهبود عملکرد است ، همانطور که از مزایای مورد بحث در بخش قبلی مشهود است. بنابراین ، چه زمانی باید در نظر داشته باشید که یک لایه حافظه پنهان به معماری برنامه خود اضافه کنید؟عوامل مختلفی برای در نظر گرفتن وجود دارد.
بیشتر برنامه ها دارای نقاط داغ داده هستند که به طور مرتب پرس و جو می شوند اما به ندرت به روز می شوند. به عنوان مثال ، اگر شما یک انجمن آنلاین را اجرا می کنید ، ممکن است یک جریان ثابت از پست های جدید وجود داشته باشد ، اما پست های قدیمی یکسان باقی می مانند و بسیاری از موضوعات قدیمی برای مدت طولانی بدون تغییر باقی می مانند. در این سناریو ، برنامه می تواند صدها یا هزاران درخواست برای همان داده های بدون تغییر دریافت کند ، که آن را به عنوان کاندیدای ایده آل برای ذخیره سازی تبدیل می کند. به طور کلی ، داده هایی که به طور مکرر به آنها دسترسی پیدا می کنند و اغلب تغییر نمی کنند یا اصلاً باید در حافظه پنهان ذخیره شوند.
نکته دیگر هنگام تصمیم گیری در مورد حافظه پنهان این است که آیا برنامه قبل از بازگشت یا ارائه برخی از داده ها نیاز به انجام پرس و جوهای پیچیده یا محاسبات دارد. برای وب سایت های با حجم بالا ، حتی عمل ساده ارائه برخی از خروجی HTML پس از بازیابی و محاسبه داده های مورد نیاز می تواند مقدار قابل توجهی از منابع را مصرف کرده و تأخیر را افزایش دهد. اگر خروجی برگشتی ، پس از محاسبه ، می تواند در چندین نمایش داده ها و عملیات مورد استفاده مجدد قرار گیرد ، معمولاً ایده خوبی است که آن را در حافظه نهان ذخیره کنید.
میزان تغییر یک قطعه از داده ها و مدت زمان تحمل داده های منسوخ نیز به میزان ذخیره آن کمک می کند. اگر داده ها به طور مکرر به گونه ای تغییر کنند که برای سؤالات بعدی قابل استفاده مجدد نباشد ، احتمالاً ارزش سربار مورد نیاز برای قرار دادن آن را در حافظه نهان ندارد. در این مورد انواع دیگر بهینه سازی ها باید در نظر گرفته شود.
ذخیره سازی می تواند راهی عالی برای بهبود عملکرد برنامه باشد ، اما لزوماً کار درستی در هر سناریو نیست. همانطور که با تمام تکنیک های بهینه سازی عملکرد ، اندازه گیری ابتدا قبل از ایجاد تغییرات اساسی برای جلوگیری از هدر رفتن زمان بهینه سازی در مورد اشتباه مهم است.
اولین قدم مشاهده وضعیت و عملکرد سیستم مورد نظر با نرخ درخواست معین است. اگر سیستم نتواند با بار پیش بینی شده همراه باشد ، یا اگر از آن برخورد کند یا از زمان تأخیر برخورد کند ، ممکن است ایده خوبی برای ذخیره اطلاعاتی باشد که سیستم با آنها کار می کند در صورتی که چنین حافظه پنهان در بسیاری از درخواست ها نسبت ضربه بالایی داشته باشدبشر
استراتژی های ذخیره سازی برای در نظر گرفتن
یک استراتژی ذخیره سازی الگویی است که برای مدیریت اطلاعات ذخیره شده از جمله نحوه جمع آوری و نگهداری حافظه نهان استفاده می شود. چندین استراتژی برای کشف وجود دارد و انتخاب صحیح برای به دست آوردن بیشترین مزایای عملکرد بسیار مهم است. استراتژی به کار رفته برای یک سرویس بازی که یک رهبری در زمان واقعی جمع می شود و باز می گردد ، با خدماتی که انواع دیگری از داده ها را ارائه می دهد ، مانند آمار COVID-19 ، که روزانه چند بار به روز می شوند ، متفاوت خواهد بود.
قبل از انتخاب راه حل ذخیره سازی ، سه سه مورد اصلی در نظر گرفته شده است:
- نوع داده های ذخیره شده.
- نحوه خواندن و نوشتن داده ها (استراتژی دسترسی به داده ها).
- چگونه حافظه پنهان داده های قدیمی یا منسوخ را اخراج می کند (خط مشی اخراج).
در بخش بعدی ، ما در مورد استراتژی های مختلف دسترسی به داده ها که بسته به نوع داده های ذخیره شده قابل استفاده هستند ، بحث خواهیم کرد.
الگوهای دسترسی به داده ها
الگوی دسترسی به داده ها به کار رفته رابطه بین منبع داده و لایه ذخیره را تعیین می کند. بنابراین ، دستیابی به این قسمت مهم است ، زیرا می تواند تفاوت معنی داری در اثربخشی حافظه پنهان شما ایجاد کند. در بقیه این بخش ، ما در مورد الگوهای دسترسی به داده های مشترک ، همراه با مزایا و معایب آنها بحث خواهیم کرد.
1. الگوی حافظه پنهان
در الگوی حافظه نهان ، داده ها فقط در صورت لزوم به حافظه پنهان بارگیری می شوند. هر زمان که مشتری درخواست داده باشد ، برنامه ابتدا لایه حافظه نهان را بررسی می کند تا ببیند آیا داده ها وجود دارد یا خیر. اگر داده ها در حافظه پنهان یافت شود ، بازیابی می شود و به مشتری باز می گردد. این به عنوان یک ضربه حافظه نهان شناخته می شود. اگر داده ها در حافظه نهان وجود نداشته باشد (یک حافظه نهان) ، برنامه از پایگاه داده پرس و جو می کند تا داده های درخواستی را بخواند و آن را به مشتری برگرداند. پس از آن ، داده ها در حافظه نهان ذخیره می شوند تا درخواست های بعدی برای همان داده ها سریعتر حل شوند.
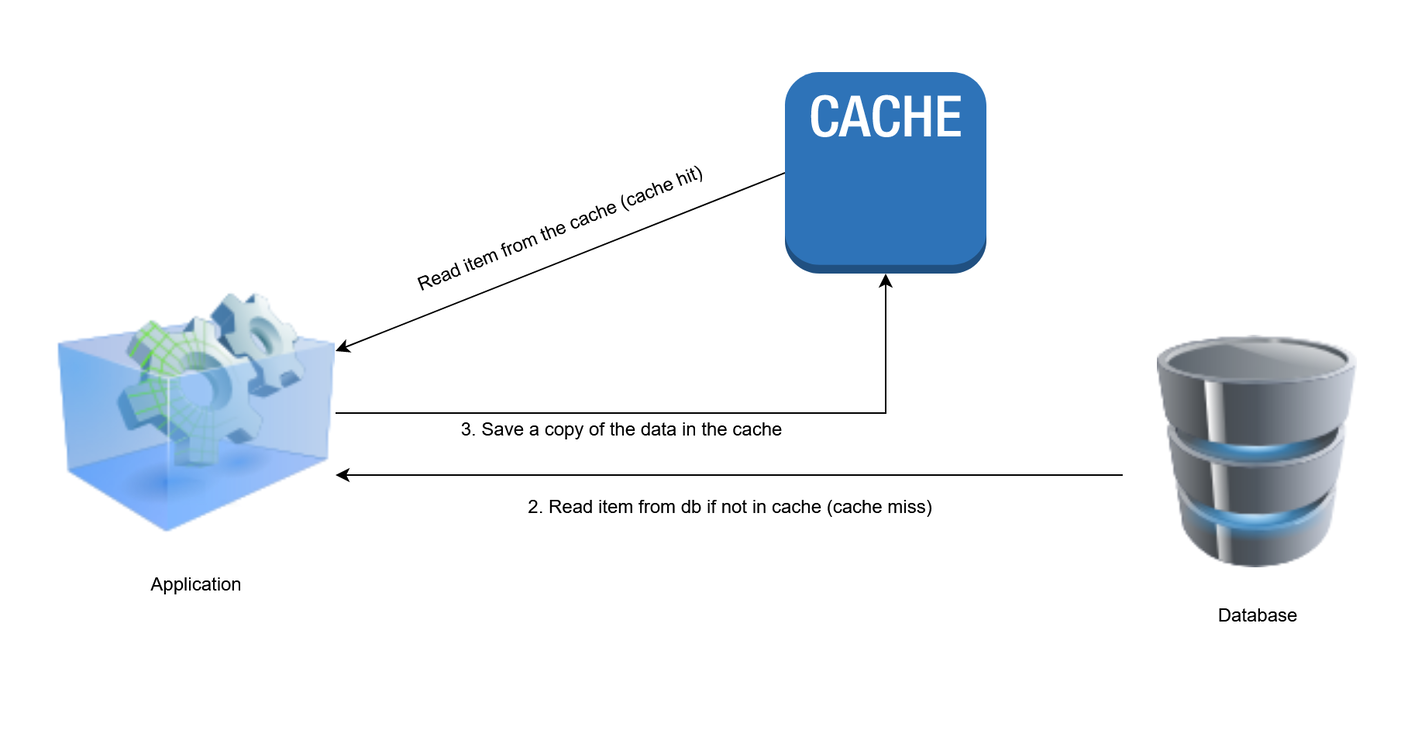
در زیر یک نمونه شبه کد از منطق حافظه پنهان است.
مزایای
- فقط داده های درخواست شده ذخیره می شوند. این بدان معنی است که حافظه پنهان با داده هایی که هرگز مورد استفاده قرار نمی گیرند پر نمی شود.
- این بهترین کار برای گردش کار سنگین است که در آن داده ها یک بار نوشته شده و چندین بار قبل از به روزرسانی مجدد (اگر اصلاً) بخوانید.
- در برابر خرابی های حافظه نهان انعطاف پذیر است. اگر لایه حافظه نهان در دسترس نباشد ، سیستم به فروشگاه داده باز می گردد. در نظر داشته باشید که یک دوره طولانی از خرابی حافظه نهان می تواند منجر به افزایش تأخیر شود.
- مدل داده موجود در حافظه نهان نیازی به نقشه برداری از آن در پایگاه داده ندارد. به عنوان مثال ، نتایج نمایش داده های مختلف پایگاه داده را می توان تحت همان شناسه در حافظه نهان ذخیره کرد.
معایب
- یک حافظه نهان ممکن است تأخیر را افزایش دهد زیرا سه عمل انجام می شود:
- داده ها را از حافظه نهان درخواست کنید.
- داده ها را از فروشگاه داده بخوانید.
- داده ها را در حافظه نهان بنویسید.
- این تضمین کننده سازگاری بین فروشگاه داده و حافظه پنهان نیست. اگر داده ها در پایگاه داده به روز شوند ، ممکن است بلافاصله در حافظه نهان منعکس نشود ، که منجر به ارائه داده های بی نظیر توسط برنامه می شود. برای جلوگیری از وقوع این امر ، الگوی حافظه نهان اغلب با استراتژی نوشتن از طریق نوشتن (که در زیر مورد بحث قرار می گیرد) ترکیب می شود ، که در آن داده ها در بانک اطلاعاتی و حافظه نهان به روز می شوند تا از داده های ذخیره شده جلوگیری کنند.
2. الگوی خواندن
در ذخیره سازی خوانده شده ، داده ها همیشه از حافظه نهان خوانده می شوند. هنگامی که یک برنامه از حافظه نهان درخواست می کند ، و در حال حاضر در حافظه نهان نیست ، از فروشگاه داده های زیرین بارگیری می شود و برای استفاده در آینده به حافظه نهان اضافه می شود. بر خلاف الگوی حافظه پنهان ، برنامه از مسئولیت خواندن و نوشتن مستقیم به پایگاه داده رهایی می یابد.
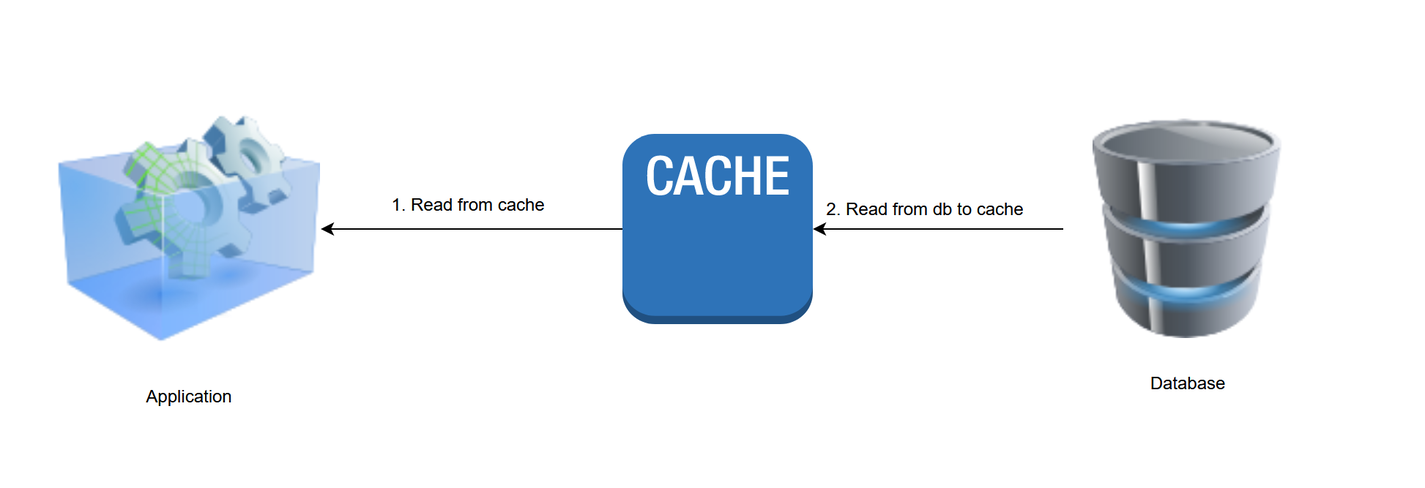
در بیشتر موارد ، شما باید یک کنترل کننده خوانده شده توسط حافظه نهان را اجرا کنید ، که به آن اجازه می دهد تا در صورت از دست دادن حافظه نهان ، داده ها را مستقیماً از پایگاه داده بخواند. در اینجا برخی از شبه کد وجود دارد که نشان می دهد چگونه می توان آن را انجام داد:
مزایای
- مانند حافظه نهان ، برای بارهای کاری خواندن سنگین که در آن بارها از همان داده ها درخواست می شود ، خوب کار می کند.
- فقط داده های درخواست شده ذخیره می شوند و از استفاده کارآمد از منابع پشتیبانی می کنند.
- این مدل به حافظه پنهان اجازه می دهد تا هنگام بروزرسانی داده ها یا زمان انقضاء حافظه نهان ، از یک شیء از پایگاه داده استفاده کند.
معایب
- مدل داده در حافظه نهان نمی تواند با مدل داده در پایگاه داده متفاوت باشد.
- برخلاف حافظه نهان ، در برابر نارسایی حافظه پنهان مقاومت نمی کند.
- در صورت عدم وجود داده های درخواست شده در حافظه نهان ، ممکن است تأخیر افزایش یابد.
- این امکان وجود دارد که داده های ذخیره شده بی رنگ شوند ، اما این مشکل را می توان با استفاده از یکی از استراتژی های نوشتن که در زیر در نظر گرفته می شود ، حل کرد.
3. الگوی نوشتن
هنگامی که از استراتژی نوشتن استفاده می شود ، لایه حافظه نهان به عنوان فروشگاه داده اصلی برنامه استفاده می شود. این بدان معنی است که داده های جدید یا به روز شده به طور مستقیم به حافظه پنهان اضافه یا به روز می شوند در حالی که وظیفه ادامه داده ها به فروشگاه داده های زیرین به لایه حافظه نهان واگذار می شود. هر دو عملیات نوشتن باید در یک معامله واحد انجام شود تا از خارج شدن داده های ذخیره شده از همگام سازی با پایگاه داده جلوگیری شود.

در زیر یک نمونه شبه کد از منطق نوشتن است.
مزایای
- داده های موجود در حافظه نهان هرگز به دلیل همگام سازی آن با پایگاه داده پس از هر عمل نوشتن ، هرگز به صورت همزمان نیستند.
- این برای سیستمهایی مناسب است که نمی توانند استحکام در حافظه پنهان را تحمل کنند.
معایب
- هنگام نوشتن داده ، تأخیر را اضافه می کند زیرا کار بیشتری با نوشتن به فروشگاه داده انجام می شود و ابتدا به حافظه نهان.
- اگر لایه حافظه نهان در دسترس نباشد ، عملیات نوشتن شکست خواهد خورد.
- حافظه نهان ممکن است داده هایی را که هرگز خوانده نمی شوند ، جمع کند و این منابع را هدر می دهد. این را می توان با ترکیب این الگوی با الگوی حافظه نهان یا با اضافه کردن یک سیاست زمان به زندگی (TTL) کاهش داد.
4. الگوی نوشتن در پشت
در الگوی نوشتن-پشت (همچنین به عنوان نوشتن-پشت نیز شناخته می شود) ، داده ها به طور مستقیم در حافظه نهان درج شده یا اصلاح می شوند و بعداً به طور غیر همزمان پس از یک تأخیر پیکربندی شده برای منبع داده نوشته می شوند ، که می تواند به اندازه چند ثانیه یا تا زمانی باشدچندین روز. پیامدهای اصلی اتخاذ این الگوی ذخیره سازی این است که به روزرسانی های پایگاه داده مدتی پس از اتمام معامله حافظه پنهان اعمال می شود ، به این معنی که شما باید تضمین کنید که پایگاه داده می نویسد با موفقیت تکمیل می شود یا راهی برای بازگرداندن به روزرسانی ها ارائه می دهد.
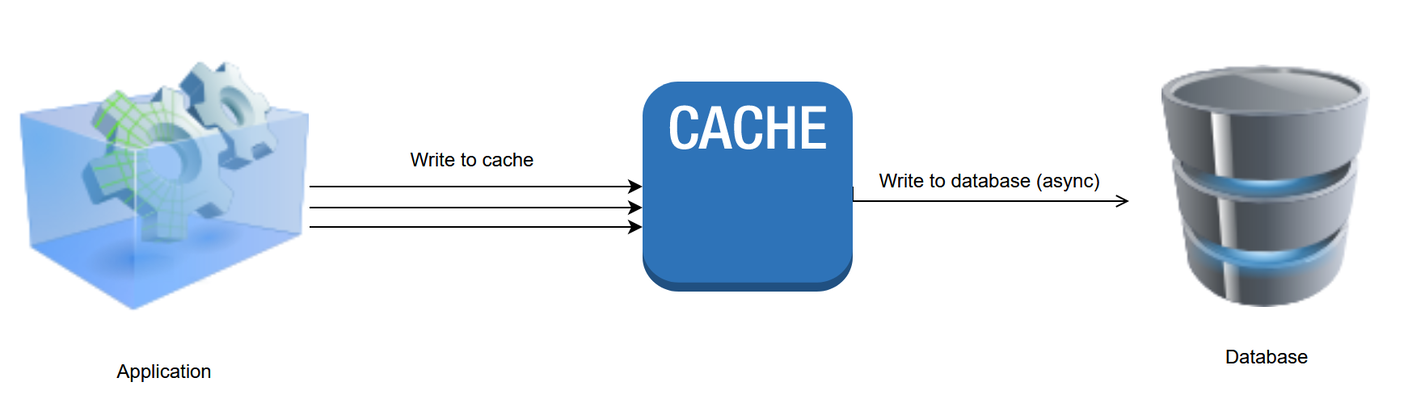
مزایای
- بهبود عملکرد نوشتن در مقایسه با نوشتن از آنجا که برنامه نیازی به انتظار برای نوشتن داده ها برای فروشگاه داده های زیرین ندارد.
- بار پایگاه داده کاهش می یابد زیرا چندین نوشتن اغلب در یک معامله پایگاه داده واحد قرار می گیرند ، که اگر تعداد درخواست ها عاملی در قیمت گذاری ارائه دهنده بانک اطلاعاتی باشد ، می تواند هزینه ها را نیز کاهش دهد.
- این برنامه تا حدودی در برابر خرابی های پایگاه داده موقت محافظت می شود زیرا می توان نوشت:
- این مناسب برای بارهای کاری سنگین نوشتن است.
معایب
- اگر خرابی حافظه پنهان وجود داشته باشد ، ممکن است داده ها به طور دائم از بین بروند. بنابراین ، ممکن است برای داده های حساس مناسب نباشد.
- عملیات انجام شده به طور مستقیم در پایگاه داده ممکن است از داده های قدیمی استفاده کند زیرا حافظه نهان و فروشگاه داده نمی تواند تضمین شود که در هر مقطع زمانی مشخص باشد.
5. الگوی تازه کردن
در الگوی تازه سازی ، داده های ذخیره شده اغلب به آنها قبل از انقضا تازه می شوند. این اتفاق به طور غیر همزمان اتفاق می افتد به طوری که برنامه هنگام بازیابی یک شیء از فروشگاه داده در صورت انقضاء آن ، اثر خواندن آهسته را احساس نمی کند.
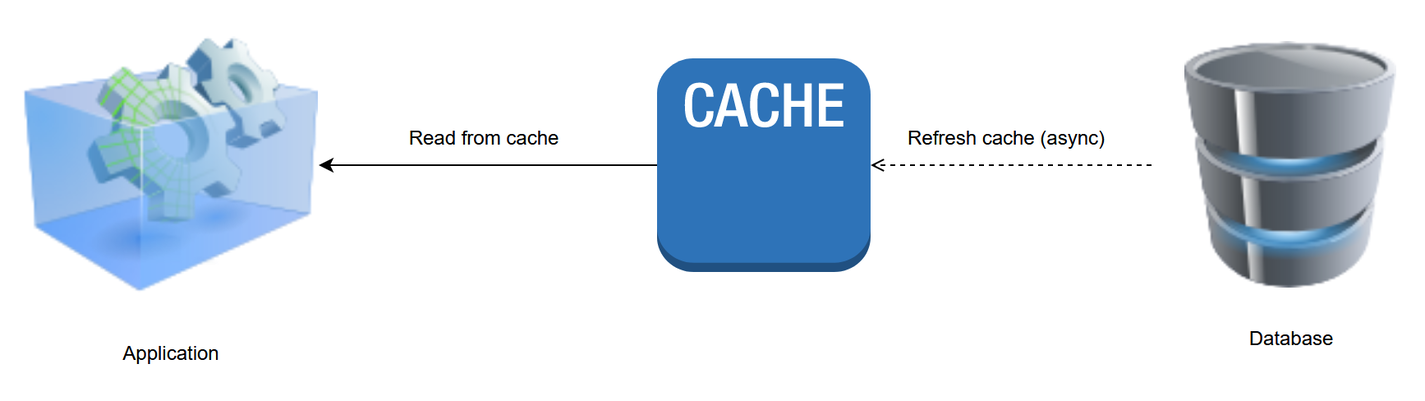
مزایای
- ایده آل هنگام خواندن داده ها از فروشگاه داده پرهزینه است.
- کمک می کند تا همیشه ورودی های حافظه نهان را همگام نگه دارید.
- ایده آل برای بار کاری حساس به تأخیر ، مانند سایت های امتیاز دهی به ورزش زنده و داشبورد مالی بازار سهام.
معایب
- حافظه نهان باید به طور دقیق پیش بینی کند که در آینده موارد حافظه نهان مورد نیاز است زیرا پیش بینی های نادرست می تواند بانک اطلاعاتی غیر ضروری را تحمل کند.
سیاست اخراج حافظه نهان
اندازه حافظه نهان معمولاً در مقایسه با اندازه پایگاه داده محدود است ، بنابراین لازم است فقط موارد مورد نیاز را ذخیره کرده و ورودی های اضافی را حذف کنید. یک سیاست اخراج حافظه نهان تضمین می کند که حافظه پنهان با حذف اشیاء قدیمی تر از حافظه نهان به عنوان موارد جدید ، از حداکثر حد خود تجاوز نمی کند. چندین الگوریتم اخراج برای انتخاب وجود دارد و بهترین آنها به نیازهای برنامه شما بستگی دارد.
هنگام انتخاب یک سیاست اخراج ، به خاطر داشته باشید که همیشه مناسب نیست که یک خط مشی جهانی را برای هر مورد موجود در حافظه نهان اعمال کنید. اگر یک شیء ذخیره شده برای بازیابی از فروشگاه داده بسیار گران باشد ، ممکن است بدون در نظر گرفتن اینکه آیا الزامات اخراج را برآورده می کند ، حفظ این مورد در حافظه نهان مفید باشد. برای دستیابی به راه حل بهینه برای مورد استفاده شما ، ممکن است ترکیبی از سیاست های اخراج نیز لازم باشد. در این بخش ، ما به برخی از محبوب ترین الگوریتم های مورد استفاده در محیط های تولیدی نگاهی خواهیم انداخت.
1. حداقل اخیراً استفاده شده (LRU)
حافظه نهان که خط مشی LRU را پیاده سازی می کند ، موارد خود را به ترتیب استفاده سازماندهی می کند. بنابراین ، اخیراً موارد مورد استفاده در بالای حافظه نهان قرار خواهد گرفت ، در حالی که کمترین مواردی که اخیراً مورد استفاده قرار می گیرند در انتهای آن قرار دارند. این امر باعث می شود که هنگام تمیز کردن حافظه نهان ، کدام موارد را باید اخراج کرد.
هر بار که به یک ورودی دسترسی پیدا می کنید ، الگوریتم LRU جدول زمانی را روی جسم به روز می کند و آن را به بالای حافظه نهان منتقل می کند. هنگامی که زمان آن رسیده است که برخی از موارد را از حافظه نهان بیرون بیاورید ، وضعیت حافظه نهان را تجزیه و تحلیل کرده و موارد را در پایین لیست حذف می کند.
2. کمترین مورد استفاده (LFU)
کمترین استفاده از الگوریتم مورد استفاده ، بر اساس میزان دسترسی به آنها ، مواردی را از حافظه نهان بیرون می کشد. این تجزیه و تحلیل با افزایش پیشخوان بر روی یک شیء ذخیره شده هر بار که به آن دسترسی پیدا می کند ، انجام می شود تا در زمان زمان اخراج موارد از حافظه نهان ، با سایر اشیاء مقایسه شود.
LFU در مواردی می درخشد که الگوهای دسترسی اشیاء ذخیره شده اغلب تغییر نمی کنند. به عنوان مثال ، دارایی ها بر اساس الگوهای استفاده بر روی CDN ذخیره می شوند به طوری که بیشترین استفاده از اشیاء هرگز از بین نمی روند. همچنین به اخراج مواردی کمک می کند که در یک دوره خاص سنبله را مشاهده می کنند اما فرکانس دسترسی پس از آن به طرز چشمگیری کاهش می یابد.
3. اخیراً مورد استفاده (MRU)
اخیراً سیاست اخراج در اصل برعکس الگوریتم LRU است زیرا موارد حافظه پنهان را بر اساس توجه به آخرین دسترسی آنها تجزیه و تحلیل می کند. تفاوت این است که به جای کمترین موارد مورد استفاده ، اخیراً اشیاء مورد استفاده از حافظه نهان را دور می کند.
یک مورد استفاده خوب برای MRU این است که بعید است که به زودی از یک شیء اخیراً قابل دسترسی استفاده شود. یک مثال می تواند حذف صندلی های پرواز رزرو شده از حافظه نهان بلافاصله پس از رزرو باشد ، زیرا آنها دیگر به یک برنامه رزرو بعدی مربوط نیستند.
4. اول در ، اول (FIFO)
حافظه نهان که FIFO را به ترتیب اضافه می کند ، بدون توجه به چند بار یا چند بار به آنها ، مواردی را به ترتیب اضافه می کند.
انقضاء حافظه نهان
سیاست انقضا به کار رفته توسط حافظه نهان عامل دیگری است که به تعیین مدت حفظ یک کالای ذخیره شده کمک می کند. خط مشی انقضا معمولاً هنگام افزودن به حافظه نهان به شیء اختصاص می یابد و اغلب برای نوع ذخیره شیء سفارشی می شود. یک استراتژی مشترک شامل اختصاص زمان مطلق انقضا به هر شی در هنگام افزودن به حافظه نهان است. پس از گذشت زمان ، این مورد منقضی می شود و بر این اساس از حافظه نهان خارج می شود. این زمان انقضا بر اساس نیازهای مشتری انتخاب می شود ، مانند تغییر سریع داده ها و تحمل سیستم نسبت به داده های بی ثبات.
یک سیاست انقضاء کشویی یکی دیگر از روشهای متداول برای باطل کردن اشیاء ذخیره شده است. این خط مشی از موارد احتمالی که اغلب توسط برنامه استفاده می شود با تمدید زمان انقضا با یک بازه مشخص در هر بار که به آنها دسترسی پیدا می کند ، حمایت می کند. به عنوان مثال ، موردی که مدت زمان انقضاء کشویی 15 دقیقه است ، تا زمانی که حداقل یک بار در هر 15 دقیقه به آن دسترسی پیدا کند ، از حافظه نهان خارج نمی شود.
شما باید هنگام انتخاب مقدار TTL برای ورودی های حافظه نهان ، عمدی داشته باشید. پس از اجرای اولیه حافظه نهان ، نظارت بر اثربخشی مقادیر انتخاب شده مهم است تا در صورت لزوم دوباره ارزیابی شوند. توجه داشته باشید که بیشتر چارچوب های ذخیره سازی ممکن است موارد منقضی شده را بلافاصله به دلایل عملکرد حذف نکنند. آنها به طور معمول از یک الگوریتم قابل استفاده استفاده می کنند ، که معمولاً هنگام مراجعه به حافظه نهان مورد استفاده قرار می گیرد ، به دنبال ورودی های منقضی شده و آنها را می اندازد. این امر مانع از پیگیری مداوم وقایع انقضا می شود تا مشخص شود چه موقع موارد باید از حافظه نهان خارج شوند.
راه حل های ذخیره سازی
روش های مختلفی برای اجرای ذخیره سازی در یک برنامه وب وجود دارد. غالباً ، پس از شناسایی نیاز به حافظه پنهان ، یک حافظه پنهان در فرآیند برای این کار استفاده می شود زیرا از نظر مفهومی ساده ، نسبتاً ساده برای اجرای آن است و می تواند با حداقل تلاش ، عملکرد قابل توجهی را انجام دهد. نکته مهم اصلی حافظه پنهان در فرآیند این است که اشیاء ذخیره شده به تنهایی به روند فعلی محدود می شوند. اگر در یک سیستم توزیع شده با چندین مورد که متعادل هستند ، به کار می روند ، به همان تعداد انبارهای مربوط به نمونه های کاربردی در پایان می توانید به یک مشکل انسجام حافظه پنهان منجر شود زیرا درخواست های مشتری بسته به نوع سرور ممکن است از داده های جدیدتر یا قدیمی تر استفاده کنند. برای پردازش آناگر فقط اشیاء تغییر ناپذیر را ذخیره کنید ، این مشکل اعمال نمی شود.
کمبود دیگر حافظه های فرآیند این است که آنها از همان منابع و فضای حافظه به عنوان خود برنامه استفاده می کنند. این امر می تواند باعث خرابی های خارج از حافظه شود اگر در حین تنظیم آن ، محدوده بالایی حافظه نهان با دقت در نظر گرفته نشود. هر زمان که برنامه مجدداً راه اندازی شود ، ذخیره های داخل فرآیند نیز شستشو می شوند و این باعث می شود وابستگی پایین دست در حالی که حافظه نهان مجدداً مجدداً بار دیگر دریافت می کند ، بار بیشتری دریافت کند. اگر از یک استراتژی استقرار مداوم در برنامه شما استفاده شود ، این یک نکته مهم است.
بسیاری از مسائل مربوط به حافظه پنهان در فرآیند را می توان با استفاده از یک راه حل ذخیره سازی توزیع شده که یک نمای واحد به حافظه نهان ارائه می دهد ، حتی اگر در یک خوشه از گره های مختلف مستقر شود ، حل شود. این بدان معنی است که اشیاء ذخیره شده بدون در نظر گرفتن تعداد سرورهای به کار رفته ، از همان مکان نوشته شده و خوانده می شوند و باعث کاهش وقوع مسائل انسجام حافظه پنهان می شوند. حافظه نهان توزیع شده نیز در طول استقرار جمع می شود زیرا مستقل از خود برنامه است و از فضای ذخیره سازی خود استفاده می کند تا شما محدود به حافظه سرور موجود نباشید.
با این گفته ، استفاده از حافظه نهان توزیع شده چالش های خاص خود را نشان می دهد. این امر با افزودن وابستگی جدیدی که باید به طور مناسب کنترل و مقیاس بندی شود ، پیچیدگی سیستم را افزایش می دهد و به دلیل تأخیر در شبکه و سریال سازی شیء کندتر از یک حافظه نهان در فرآیند است. حافظه نهان توزیع شده نیز ممکن است هر از گاهی در دسترس نباشد (به عنوان مثال ، به دلیل نگهداری و به روزرسانی ها) ، و منجر به تخریب عملکرد قابل توجه ، به ویژه در دوره های قطع طولانی مدت می شود. اگر حافظه نهان توزیع شده در دسترس نباشد ، می توان این مسئله را با بازگشت به حافظه نهان فرآیند کاهش داد.
حافظه پنهان در فرآیند ممکن است در یک برنامه Node. js از طریق کتابخانه ها مانند گره-کارت ، حافظه-حافظه ، API-Cache و سایر موارد اجرا شود. طیف گسترده ای از راه حل های ذخیره سازی توزیع شده وجود دارد ، اما محبوب ترین آنها Redis و Memcached هستند. آنها هر دو فروشگاه های با ارزش کلیدی در حافظه هستند و به دلیل استفاده از حافظه به جای مکانیسم های ذخیره سازی کندتر روی دیسک که در سیستم های پایگاه داده سنتی یافت می شود ، به دلیل استفاده از حافظه بهینه و یا بارهای کاری با محاسبه سنگین و یا بار کاری محاسبه شده بهینه هستند.
حافظه پنهان در فرآیند با گره گره
در زیر مثالی وجود دارد که نشان می دهد چگونه می توان حافظه پنهان در فرآیند را بدون نیاز به یک فرآیند تنظیم پیچیده انجام داد. این برنامه ساده NodeJS از گره و نه از الگوی حافظه پنهان استفاده شده در این پست برای سرعت بخشیدن به درخواست های بعدی برای لیستی از پست ها از یک API خارجی استفاده می کند.
هنگامی که اولین درخواست به مسیر /پست ها انجام می شود ، حافظه نهان خالی است ، بنابراین برای بازیابی داده های لازم باید به یک API خارجی دسترسی پیدا کنیم. هنگامی که من زمان پاسخ را برای درخواست اولیه آزمایش کردم ، برای دریافت پاسخ حدود 1. 2 ثانیه طول کشید.
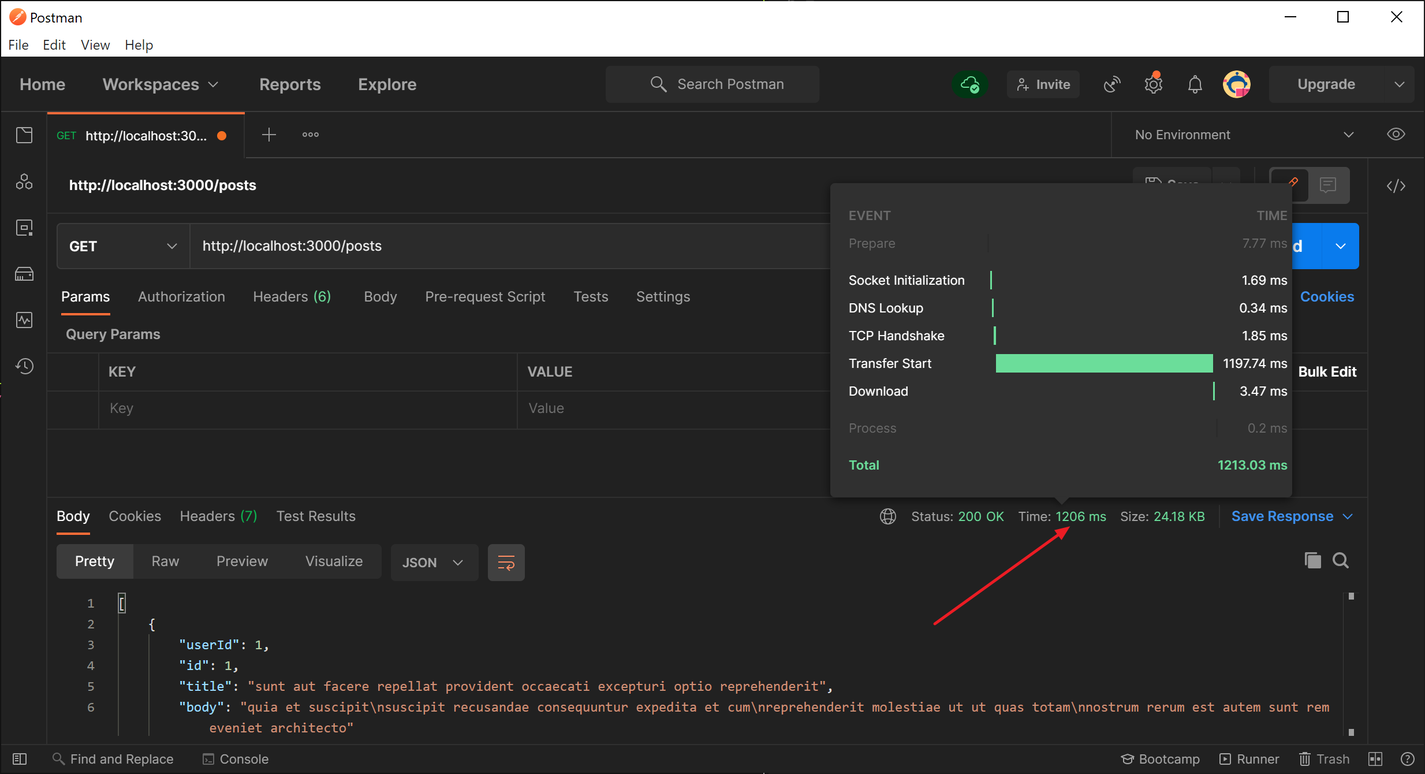
پس از بازیابی داده ها از API ، در حافظه نهان ذخیره می شود ، که باعث می شود درخواست های بعدی زمان قابل توجهی کمتری برای حل و فصل داشته باشد. در تست های من ، من به طور مداوم حدود 20-25 بار پاسخ در درخواست های بعدی دریافت کردم ، که نشان دهنده تقریباً 6000 ٪ بهبود عملکرد نسبت به ایجاد یک درخواست شبکه برای داده ها است.
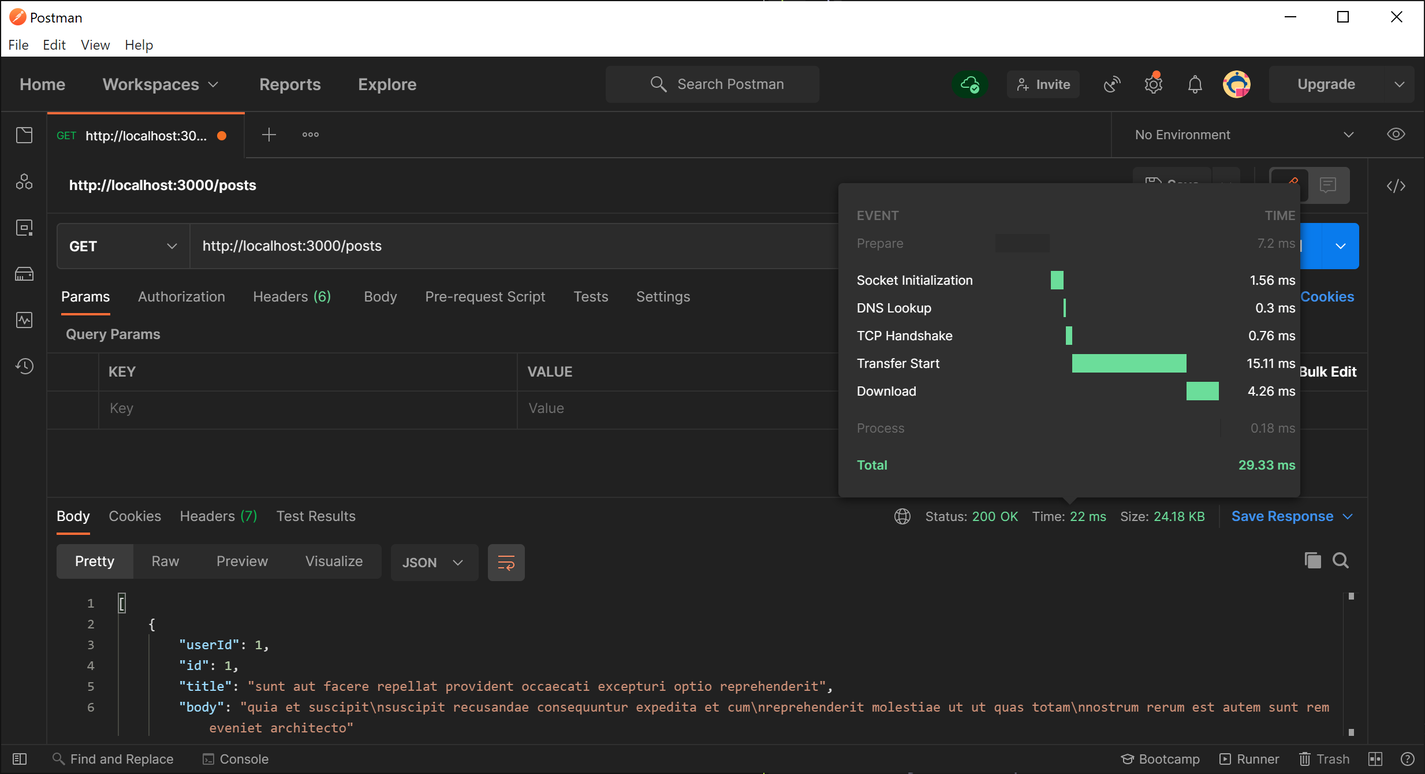
ذخیره با redis
Redis تقریباً راه حل ذخیره سازی توزیع شده برای نه تنها Node. js بلکه زبانهای دیگر است. این مثال نشان می دهد که چگونه یک لایه حافظه نهان ممکن است با استفاده از redis به یک برنامه node. js اضافه شود. مشابه مثال قبلی با استفاده از گره-مخزن ، داده های ذخیره شده از API بازیابی می شوند.
اطمینان حاصل کنید که قبل از امتحان کردن کد نمونه در زیر ، Redis نصب شده اید. شما ممکن است راهنمای رسمی QuickStart را دنبال کنید تا یاد بگیرید که چگونه آن را به کار بگیرید و کار کنید. علاوه بر این ، قبل از اجرای برنامه ، اطمینان حاصل کنید که وابستگی های لازم را نصب کنید. این مثال از کتابخانه Node-Redis استفاده می کند.
در مثال بالا ، آمار جهانی COVID-19 از API بازیابی می شود و از طریق مسیر /COVID به مشتری باز می گردد. این آمار به مدت 1 ساعت (3600 ثانیه) در Redis ذخیره می شود تا اطمینان حاصل شود که درخواست های شبکه به حداقل می رسد. Redis همه چیز را به عنوان یک رشته ذخیره می کند ، بنابراین شما باید هنگام ذخیره آن در حافظه نهان ، اشیاء را به یک رشته با json. stringify () تبدیل کنید و سپس پس از بازیابی آن از حافظه نهان ، به یک شی با json. parse () برگردید ، همانطور که در بالا نشان داده شده است. بشر
توجه کنید که چگونه از روش SetEx برای ذخیره داده ها در حافظه نهان به جای روش تنظیم منظم استفاده می شود. در اینجا ترجیح داده می شود زیرا به ما امکان می دهد زمان انقضا را برای شیء ذخیره شده تعیین کنیم. هنگامی که زمان مشخصی سپری می شود ، Redis به طور خودکار از شیء از حافظه نهان خلاص می شود تا با فراخوانی دوباره API ، آن را تازه کند.
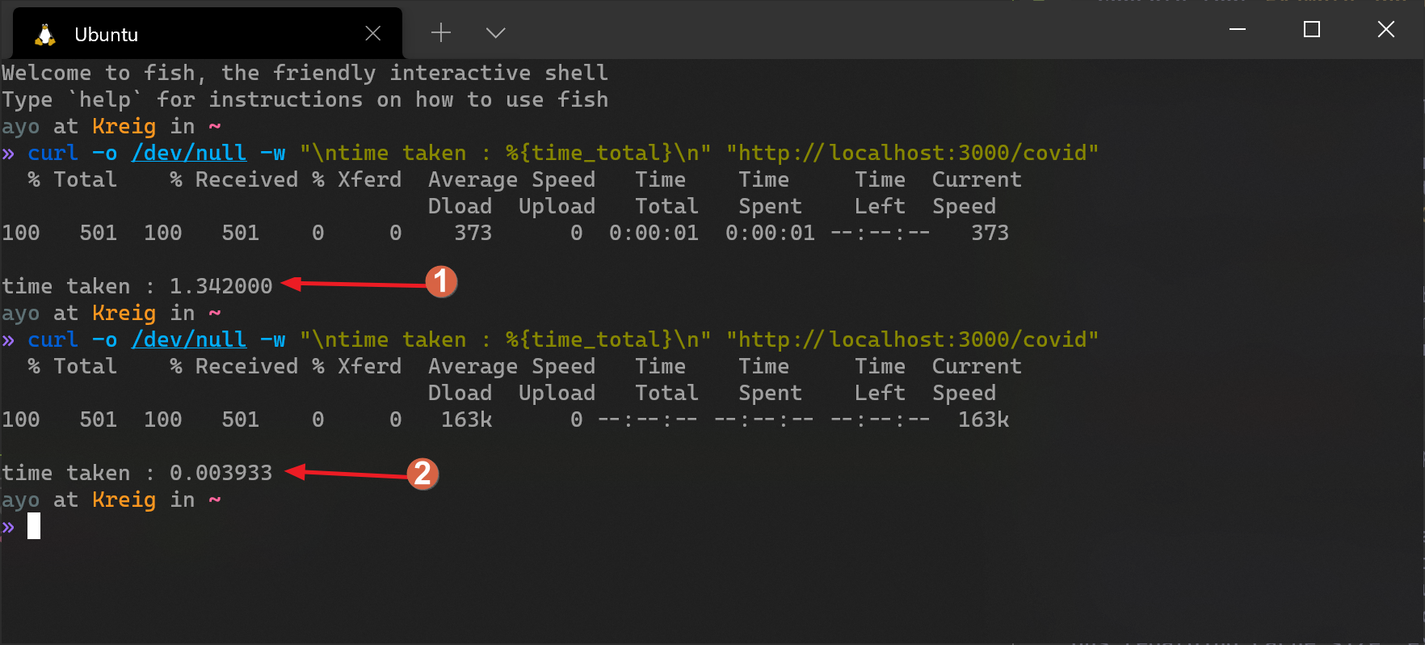
ملاحظات دیگر
در اینجا برخی از بهترین روشهای کلی که باید قبل از اجرای حافظه پنهان در برنامه خود در نظر بگیرید:
- اطمینان حاصل کنید که داده ها قابل ذخیره هستند و نرخ ضربه ای را به اندازه کافی بالا برای توجیه منابع اضافی مورد استفاده در ذخیره سازی آن به همراه خواهد داشت.
- برای اطمینان از تنظیم مناسب ، معیارهای زیرساخت ذخیره خود (مانند نرخ ضربه و مصرف منابع) را کنترل کنید. از بینش های به دست آمده برای اطلاع رسانی در مورد تصمیمات بعدی در مورد اندازه حافظه نهان ، انقضا و سیاست های اخراج استفاده کنید.
- اطمینان حاصل کنید که سیستم شما در برابر خرابی حافظه نهان مقاوم است. با سناریوهایی مانند عدم دسترسی به حافظه نهان ، خرابی های حافظه پنهان/دریافت و خطاهای پایین دست مستقیماً در کد خود مقابله کنید.
- در صورت حفظ داده های حساس در حافظه نهان ، خطرات امنیتی را با استفاده از تکنیک های رمزگذاری کاهش دهید.
- اطمینان حاصل کنید که برنامه شما در برابر تغییر در قالب ذخیره سازی مورد استفاده برای داده های ذخیره شده مقاومت می کند. نسخه های جدید برنامه شما باید قادر به خواندن داده هایی باشد که نسخه قبلی آن را برای حافظه نهان نوشت.
نتیجه
ذخیره سازی موضوعی پیچیده است که نباید به آرامی با آن رفتار کرد. هنگامی که به درستی اجرا شوید ، پاداش های عظیمی را به دست خواهید آورد ، اما اگر راه حل اشتباه را اتخاذ کنید ، می تواند به راحتی منبع غم و اندوه باشد. امیدوارم این مقاله به شما کمک کند تا در جهت درست کردن ، مدیریت و اجرای حافظه نهان برنامه شما در جهت درست حرکت کند.
با تشکر از خواندن ، و برنامه نویسی مبارک!
HoneyBadger به شما کمک می کند تا قبل از اینکه کاربران حتی بتوانند آنها را گزارش دهند ، خطاها را پیدا و رفع کنید. در عرض چند دقیقه تنظیم کنید و نظارت بر لیست کارهای خود را بررسی کنید.
هر ماه اخبار ، بهترین شیوه ها و داستانهای جامعه DevOps & Monitoring را به اشتراک می گذاریم - به طور گسترده برای توسعه دهندگان مانند شما.

ayooluwa Isaiah
AYO یک توسعه دهنده با علاقه شدید به فناوری وب ، امنیت و عملکرد است. او همچنین از ورزش ، خواندن و عکاسی لذت می برد.
- ayisaiah نویسنده توییتر
مقالات بیشتر جاوا اسکریپت
- 22 دسامبر 2022 استفاده از استثناء در JavaScript
- 05 دسامبر 2022 ساختمان در API Reddit با JavaScript
- 27 اکتبر 2022 مقایسه کتابخانه های بابل ، ساکراس و مشابه
- 20 اکتبر 2022 نحوه استفاده از برنامه Django و React
- 29 سپتامبر 2022 نوشتن JavaScript با ماژول ها
- 15 سپتامبر ، 2022 Multithreading در JavaScript با کارگران وب
- 22 آگوست 2022 استقرار یک برنامه Node. js با AWS Elastic Beanstalk
- 25 ژوئیه 2022 هر آنچه را که باید در مورد نقشه های واردات JavaScript بدانید
- 11 ژوئیه 2022 مقایسه کتابخانه های مؤلفه React
- 23 ژوئن 2022 مقایسه مدیران محیط Node. js
تنها ابزار نظارت بر سلامت برنامه را امتحان کنید که به شما امکان می دهد خطاهای برنامه ، به موقع و مشاغل CRON را در یک پلت فرم ساده ردیابی کنید.
- بدانید چه موقع خطاهای بحرانی رخ می دهد ، و مشتریان تحت تأثیر قرار می گیرند.
- هنگامی که سیستم های شما پایین می آیند فوراً پاسخ دهید.
- سلامت سیستم های خود را به مرور زمان بهبود بخشید.
- قبل از اینکه مشتریان بتوانند آنها را گزارش دهند ، مشکلات را برطرف کنید!
به عنوان توسعه دهندگان خودمان ، ما از هدر رفتن زمان پیگیری خطاها متنفریم - بنابراین ما سیستمی را که همیشه می خواستیم ساختیم.
HoneyBadger همه چیز را که شما نیاز دارید ردیابی می کند و هیچ چیز دیگری را ندارید ، ایجاد یک راه حل ساده برای نگه داشتن برنامه و خطای برنامه خود ، بنابراین می توانید آنچه را که انجام می دهید انجام دهید - کد جدید را آزاد کنید. آن را رایگان امتحان کنید و خودتان را ببینید.

"ما به بسیاری از سیستم های مدیریت خطا نگاه کرده ایم. Honeybadger سر و شانه های بالاتر از بقیه است و به نوعی با هر نسخه جدید بهتر می شود."- مایکل اسمیت ، بنیانگذار و CTO از ایوبلو
Honeybadger به شرکتهای برتر مانند:
ما به سیستم های مدیریت خطا زیادی نگاه کرده ایم. Honeybadger سر و شانه های بالاتر از بقیه است و به نوعی با هر نسخه جدید بهتر می شود. "
مایکل اسمیت
آیا برای نظارت خود از Sentry ، Rollbar ، Bugsnag یا Airbrake استفاده می کنید؟HoneyBadger شامل ردیابی خطا با مجموعه کاملی از ابزارهای نظارت شگفت انگیز است - همه احتمالاً کمتر از آنچه اکنون پرداخت می کنید. کشف کنید که چرا بسیاری از شرکت ها در اینجا به Honeybadger می روند.
حفر از طریق سیاهههای مربوط به چت را متوقف کنید تا یک اشکال را که در ماه گذشته ذکر شده است ، پیدا کنید. ردیاب شماره داخلی Honeybadger بحث و گفتگو را در مورد هر خطا محوری نگه می دارد ، به طوری که اگر دوباره ظاهر شود ، می توانید در جایی که از کار خارج شده اید ، انتخاب کنید.

کریس پاتون
کتاب دستیار معامله گر...
ما را در سایت کتاب دستیار معامله گر دنبال می کنید
برچسب : نویسنده : پرویز صیاد بازدید : 69
آرشیو مطالب
لینک دوستان
- کرم سفید کننده وا
- دانلود آهنگ جدید
- خرید گوشی
- فرش کاشان
- بازار اجتماعی رایج
- خرید لایسنس نود 32
- هاست ایمیل
- خرید بانه
- خرید بک لینک
- کلاه کاسکت
- موزیک باران
- دانلود آهنگ جدید
- ازن ژنراتور
- نمایندگی شیائومی مشهد
- مشاوره حقوقی تلفنی با وکیل
- کرم سفید کننده واژن
- اگهی استخدام کارپ
- دانلود فیلم
- آرشیو مطالب
- فرش مسجد
- دعا
- لیزر موهای زائد
- رنگ مو
- شارژ
خبرنامه
